Explain Image Classification by SHAP Deep Explainer
Goal¶
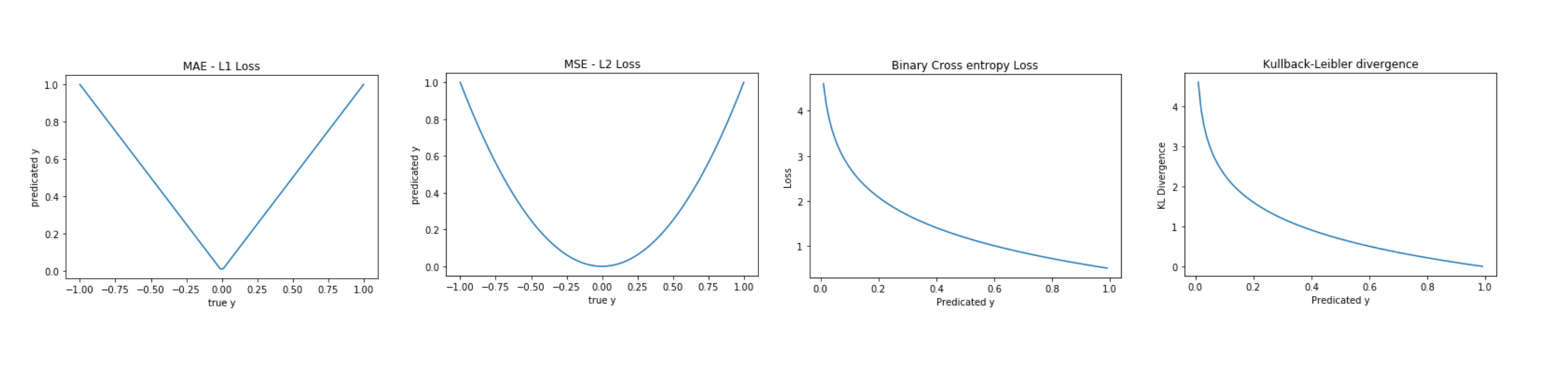
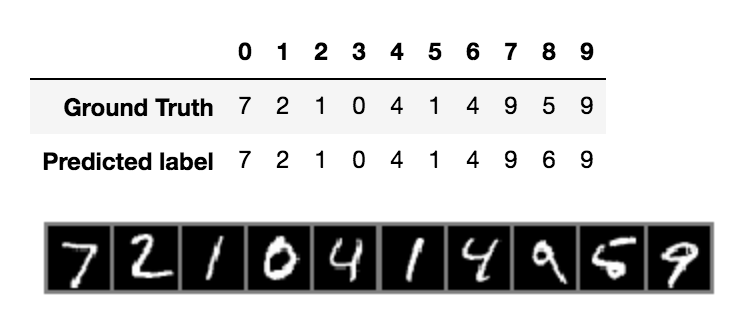
This post aims to introduce how to explain Image Classification (trained by PyTorch) via SHAP Deep Explainer.
Shap is the module to make the black box model interpretable. For example, image classification tasks can be explained by the scores on each pixel on a predicted image, which indicates how much it contributes to the probability positively or negatively.
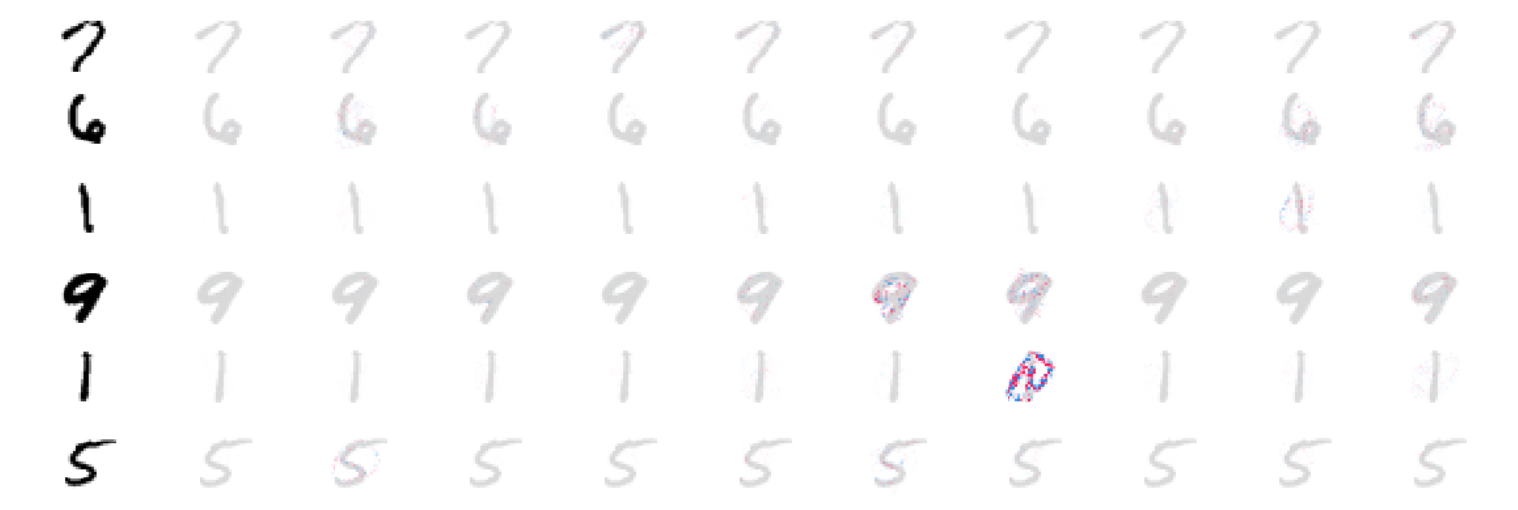
Reference