t-Test Basic
T-test Basic¶
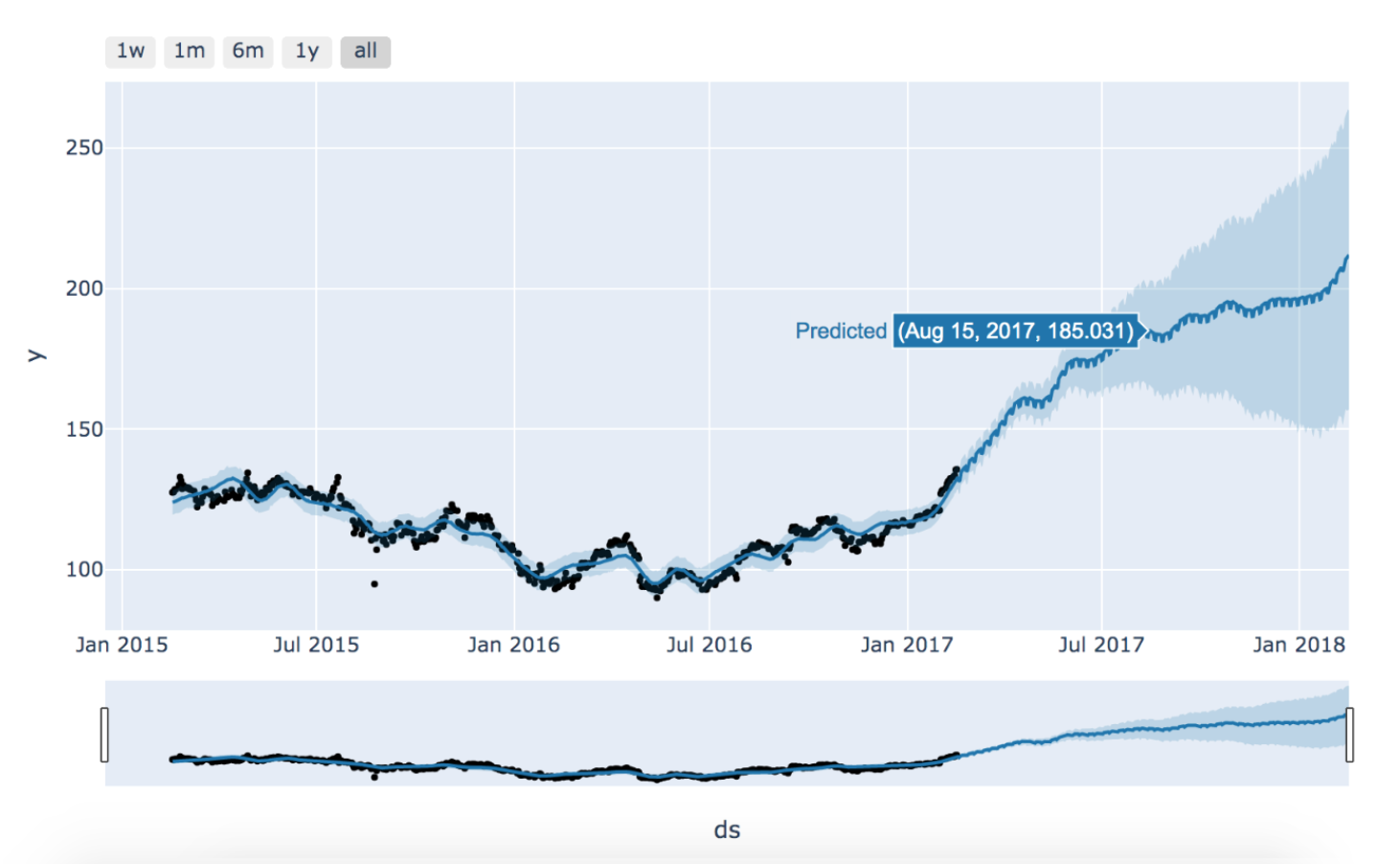
This post covers one of the simplest hypothesis test, so-called T-test. Let's say you subscribe coffee beans weekly basis and measure the weight of each coffee beans bags and obtained the following observation.
Now the package says this coffee beans is 16 oz i.e., 453.592 g. Is this actually true from statistical point of view?
In [8]:
import pandas as pd
import numpy as np
import scipy as sp
from scipy import stats
from icecream import ic
In [34]:
beans = pd.Series([448.2, 451.2, 448.0, 452.5, 447.8, 446.7])
Manual Calculation for P-value and t-value¶
In [43]:
# mu_0 for Null Hypothesis
mu0 = 453.592
# Sample size
n = len(beans)
ic(n)
# Sample Mean
mu = beans.mean()
ic(mu)
# Degree of Freedam
dof = n - 1
ic(dof)
# Sample Stnadard Deviation
sigma = beans.std(ddof=1)
ic(sigma)
# Standard Error
se = sigma / np.sqrt(n)
ic(se)
# t-value
t = (mu - mu0) / se
ic(t)
# p-value - 2 * (1 - cdf(|ts|))
p = (1 - stats.t.cdf(abs(t), df=dof)) * 2
ic(p);
Using scipy module¶
In [37]:
# Use scipy stats
stats.ttest_1samp(beans, mu0)
Out[37]:
If p-value is typically lower than 0.05 (alpha), we can rejust null-hypothesis (its population mean is mu0) and conclude this sample mean is significantly different from mu0.