Normalizing Observations
Goal¶
This post aims to introduce how to normalize the observations including the followings:
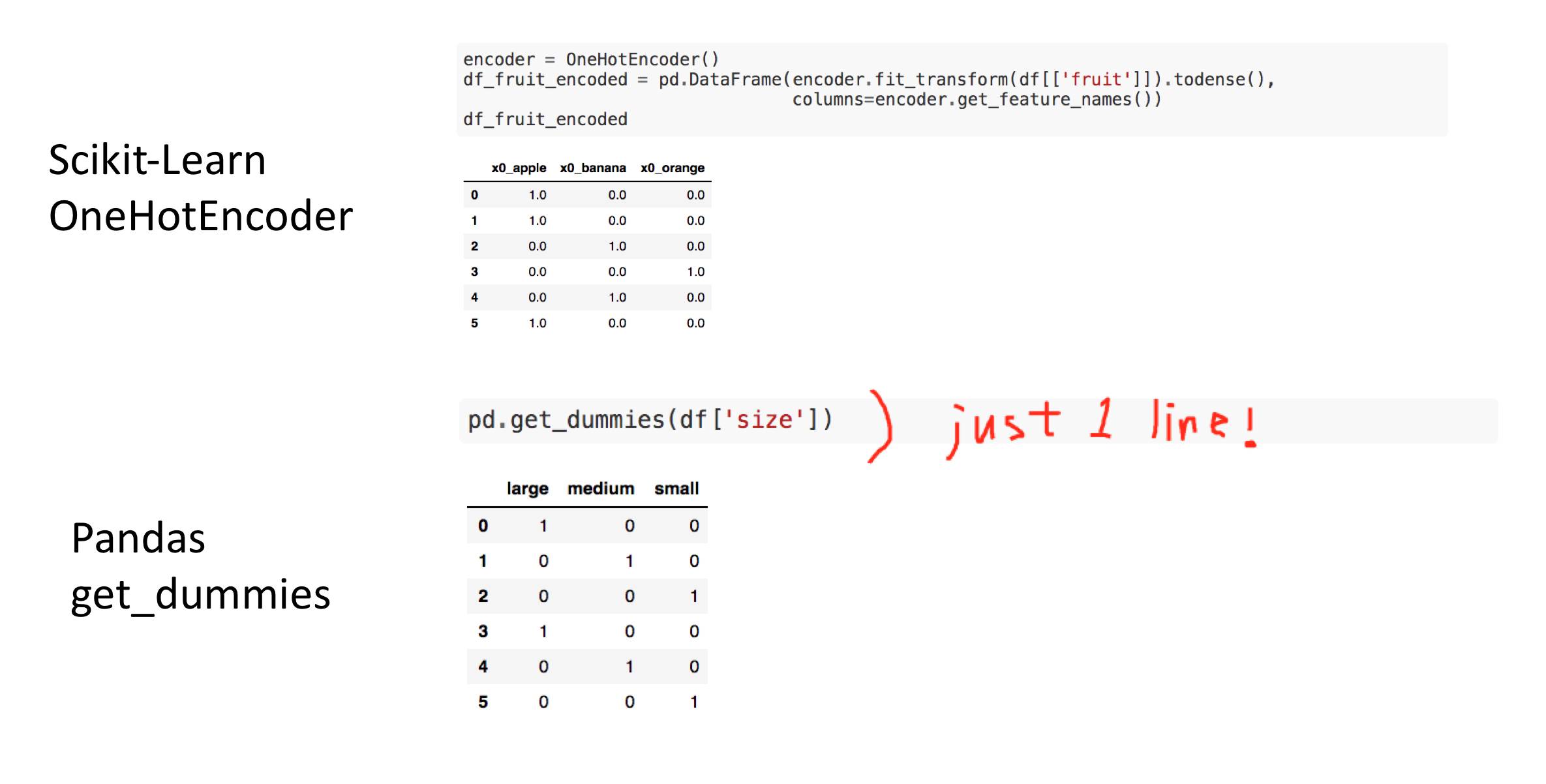
- Min-Max scaling
- Standard scaling

Libraries¶
In [53]:
import pandas as pd
import numpy as np
from sklearn.preprocessing import minmax_scale, StandardScaler
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.simplefilter('ignore')
Create a data¶
In [63]:
df = pd.DataFrame(data=60*np.random.randn(100)+20)
df.describe()
Out[63]:
In [64]:
df.hist();
plt.title('Original Data');

Normalizing¶
Min-Max Scaling¶
$$x_{min-max\,normalized} =\frac{x - min(x)}{max(x) - min(x)} $$In [65]:
data_minmax = minmax_scale(df, feature_range=(0, 1))
pd.DataFrame(pd.Series(data_minmax.ravel()).describe())
Out[65]:
In [72]:
plt.hist(data_minmax);
plt.title('Min-Max Scaled Data');
plt.axvline(x=np.min(data_minmax), ls=':', c='C0', label='Min');
plt.axvline(x=np.max(data_minmax), ls=':', c='C1', label='Max');
plt.legend();

Standard Scaler¶
This scaling assumes that the data is sampled from Normal distribution. $$x_{standard\,normalized} = \frac{x - mean(x)}{std(x)}$$
In [67]:
ss = StandardScaler()
ss.fit(df)
data_standard_scaled = ss.transform(df)
In [68]:
pd.DataFrame(pd.Series(data_standard_scaled.ravel()).describe())
Out[68]:
In [88]:
plt.axvspan(xmin=np.mean(data_standard_scaled)-3*np.std(data_standard_scaled), xmax=np.mean(data_standard_scaled)+3*np.std(data_standard_scaled), color='red', alpha=0.05,label=r'$Mean \pm 3\sigma$');
plt.hist(data_standard_scaled);
plt.title('Standard Scaled Data');
plt.axvline(x=np.mean(data_standard_scaled), ls='-.', c='red', label='Mean');
plt.legend();