Dimensionality Reduction With PCA
Goal¶
This post aims to introduce how to conduct dimensionality reduction with Principal Component Analysis (PCA).
Dimensionality reduction with PCA can be used as a part of preprocessing to improve the accuracy of prediction when we have a lot of features that has correlation mutually.
The figure below visually explains what PCA does. The blue dots are original data points in 2D. The red dots are projected data onto 1D rotating line. The red dotted line from blue points to red points are the trace of the projection. When the moving line overlaps with the pink line, the projected dot on the line is most widely distributed. If we apply PCA to this 2D data, 1D data can be obtained on this 1D line.
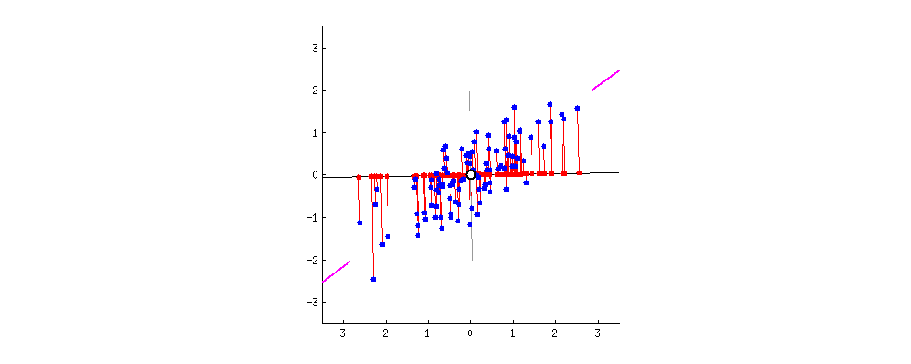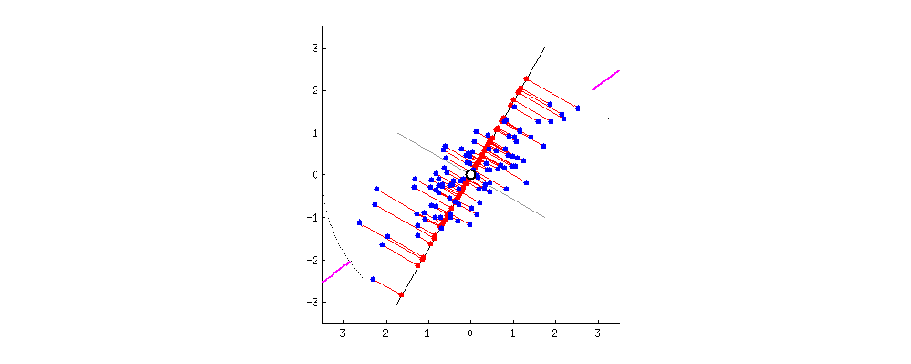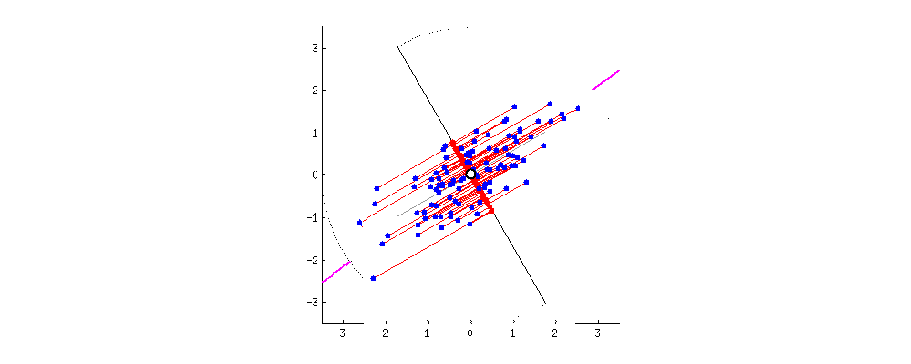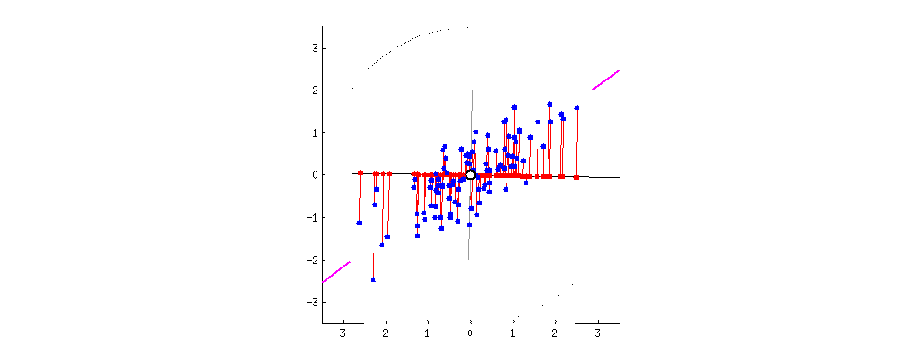
Reference
Libraries¶
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt
%matplotlib inline
Create dataset¶
wine = load_wine()
df_wine = pd.DataFrame(wine['data'], columns=[wine['feature_names']])
print('df_wine.shape:', df_wine.shape)
df_wine.head()
Apply Normalization¶
Typically, normalization would be applied before PCA since one of the variable with larger numbers could be dominant to explain the variance.
scaler = StandardScaler()
df_wine_norm = pd.DataFrame(scaler.fit_transform(df_wine))
df_wine_norm.head()
# Mean is close to 0, and std is close to 1
df_wine_norm.describe()
Apply PCA¶
pca = PCA()
df_wine_pca = pd.DataFrame(pca.fit_transform(df_wine_norm))
df_wine_pca.head()
fig, axes = plt.subplots(1, 2, figsize=(9, 3))
axes[0].plot(pca.explained_variance_);
axes[0].set_title('Explained Variance')
axes[1].plot(np.cumsum(pca.explained_variance_ratio_));
axes[1].axhline(y=0.95, c='r', ls='-.')
axes[1].set_title('Cumulative Explained Variance Ratio')
plt.tight_layout()

Normalization & PCA together by Pipeline¶
In the below case, the number of principal component is automatically selected to 5.
pipeline = Pipeline([('scaling', StandardScaler()), ('pca', PCA(n_components=5))])
df_wine_pca_pipe = pd.DataFrame(pipeline.fit_transform(df_wine))
df_wine_pca_pipe.head()
Comments
Comments powered by Disqus