Feature Importance
Goal¶
This post aims to introduce how to obtain feature importance using random forest and visualize it in a different format
Reference
Libraries¶
In [29]:
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Configuration¶
In [69]:
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (16, 6)
Load data¶
In [3]:
boston = load_boston()
df_boston = pd.DataFrame(data=boston.data, columns=boston.feature_names)
df_boston.head()
Out[3]:
Train a Random Forest Regressor¶
In [56]:
reg = RandomForestRegressor(n_estimators=50)
reg.fit(df_boston, boston.target)
Out[56]:
Obtain feature importance¶
average feature importance¶
In [70]:
df_feature_importance = pd.DataFrame(reg.feature_importances_, index=boston.feature_names, columns=['feature importance']).sort_values('feature importance', ascending=False)
df_feature_importance
Out[70]:
all feature importance for each tree¶
In [58]:
df_feature_all = pd.DataFrame([tree.feature_importances_ for tree in reg.estimators_], columns=boston.feature_names)
df_feature_all.head()
Out[58]:
In [97]:
# Melted data i.e., long format
df_feature_long = pd.melt(df_feature_all,var_name='feature name', value_name='values')
Visualize feature importance¶
The feature importance is visualized in the following format:
- Bar chart
- Box Plot
- Strip Plot
- Swarm Plot
Factor plot
Bar chart¶
In [71]:
df_feature_importance.plot(kind='bar');

Box plot¶
In [98]:
sns.boxplot(x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);

Strip Plot¶
In [99]:
sns.stripplot(x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);

Swarm plot¶
In [78]:
sns.swarmplot(x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);

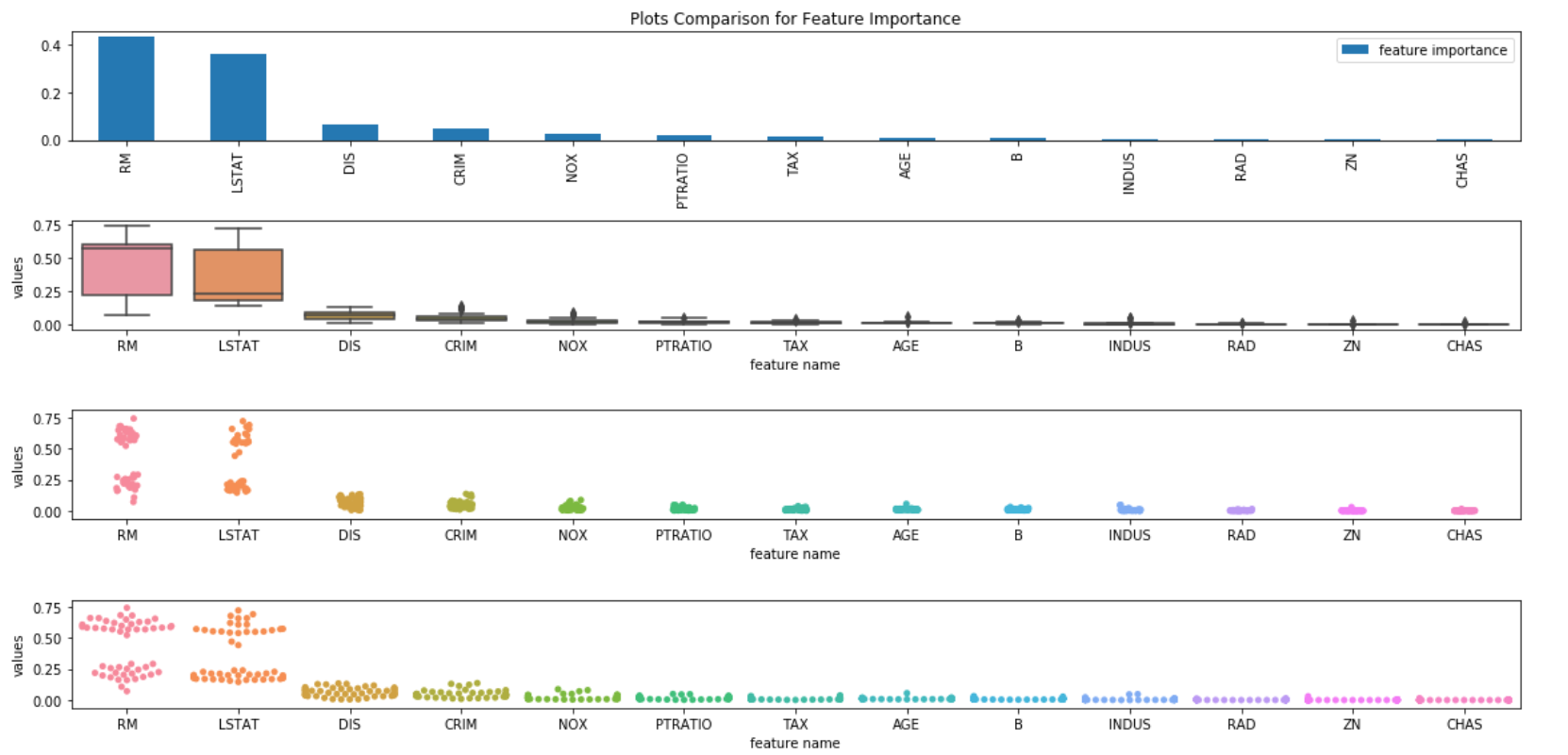
All¶
In [108]:
fig, axes = plt.subplots(4, 1, figsize=(16, 8))
df_feature_importance.plot(kind='bar', ax=axes[0], title='Plots Comparison for Feature Importance');
sns.boxplot(ax=axes[1], x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);
sns.stripplot(ax=axes[2], x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);
sns.swarmplot(ax=axes[3], x="feature name", y="values", data=df_feature_long, order=df_feature_importance.index);
plt.tight_layout()

Comments
Comments powered by Disqus