One-Hot Encode Nominal Categorical Features
Goal¶
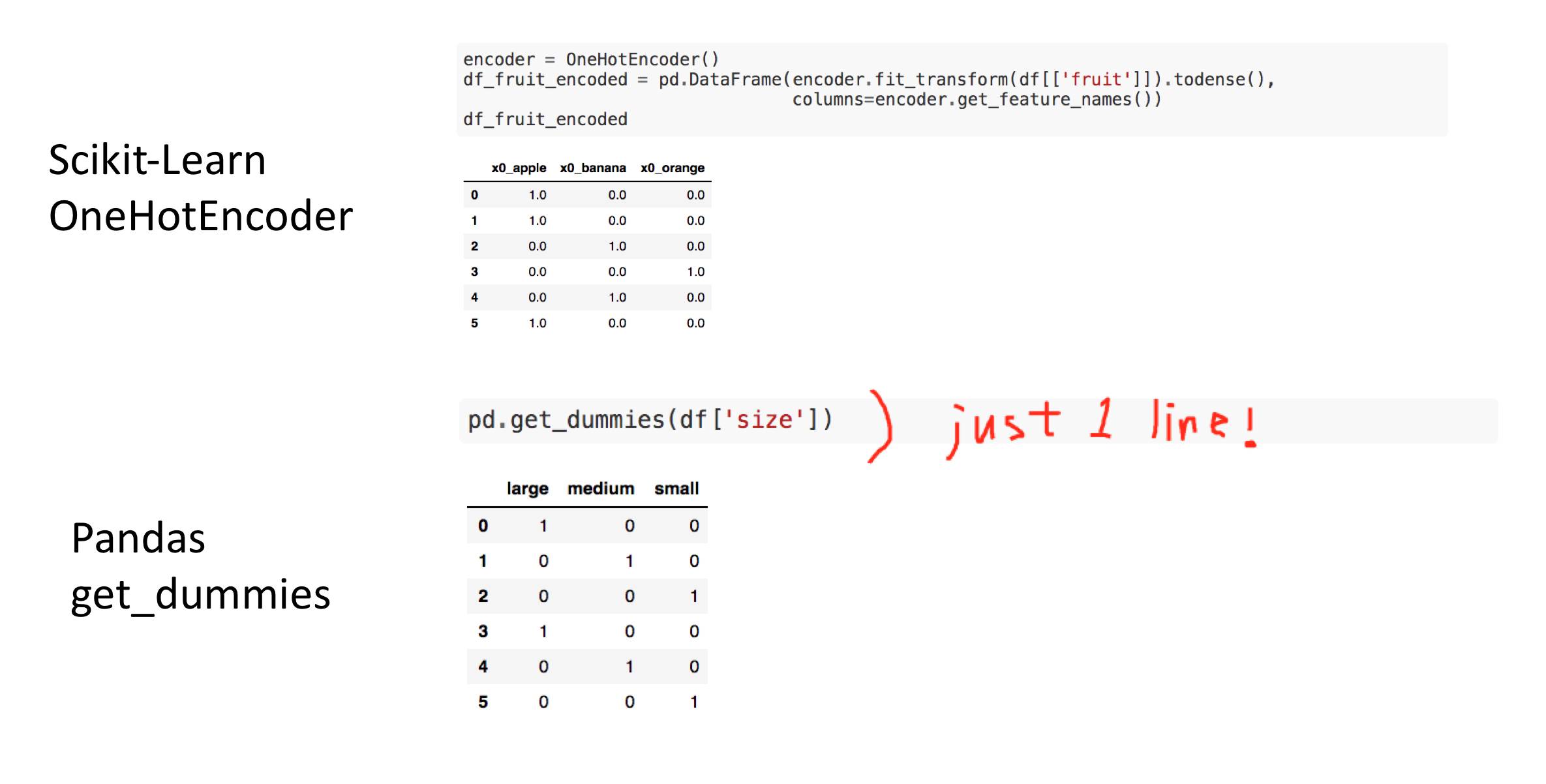
This post aims to introduce how to create one-hot-encoded features for categorical variables. In this post, two ways of creating one hot encoded features: OneHotEncoder in scikit-learn and get_dummies in pandas.
Peronally, I like get_dummies in pandas since pandas takes care of columns names, type of data and therefore, it looks cleaner and simpler with less code.
Reference
Libraries¶
In [1]:
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
Create a data for one hot encoding¶
In [4]:
df = pd.DataFrame(data={'fruit': ['apple', 'apple', 'banana', 'orange', 'banana', 'apple'],
'size': ['large', 'medium', 'small','large', 'medium', 'small']})
df
Out[4]:
Create one-hot encoded columns¶
Using OneHotEncoder in sklearn¶
In [17]:
encoder = OneHotEncoder()
df_fruit_encoded = pd.DataFrame(encoder.fit_transform(df[['fruit']]).todense(),
columns=encoder.get_feature_names())
df_fruit_encoded
Out[17]:
Using get_dummies method in pandas¶
In [18]:
pd.get_dummies(df['size'])
Out[18]:
Comments
Comments powered by Disqus