Sentiment Analysis by SHAP with Logistic Regression
Goal¶
This post aims to introduce how to do sentiment analysis using SHAP with logistic regression.
Reference
Libraries¶
In [4]:
import sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import shap
%matplotlib inline
shap.initjs()

Load the IMDB dataset¶
In [5]:
corpus, y = shap.datasets.imdb()
corpus_train, corpus_test, y_train, y_test = train_test_split(corpus,
y,
test_size=0.2,
random_state=7)
"Review" example in the corpus¶
In [18]:
# Example of one review
corpus_train[0][:200]
Out[18]:
In [10]:
# Target value
y[0]
Out[10]:
Length of each review¶
In [102]:
df_len = pd.DataFrame({'length of each review':[len(c) for c in corpus]})
In [103]:
df_len.hist(bins=100);

In [59]:
pd.Series(y).value_counts().plot(kind='bar', title='Y Label for Corpus');

Preprocessing¶
We obtain the apply TFID vectorization to convert a collection of words to a matrix of TF-IDF features.
In [68]:
# Instanciate vectorizer
vectorizer = TfidfVectorizer(min_df=10)
In [69]:
# Train vectorizer
X_train = vectorizer.fit_transform(corpus_train)
# Apply vectorizer to test data
X_test = vectorizer.transform(corpus_test)
Preprocessed data¶
After applying TFID vecterization, we will obtain the score in a large dimension. In this case, the dimension size is 16416.
In [70]:
X_test[0].shape
Out[70]:
In [71]:
X_test[:5].data[:5]
Out[71]:
Train the logistic regression¶
In [72]:
reg = sklearn.linear_model.LogisticRegression(penalty="l2",
C=0.1,
solver='lbfgs')
reg.fit(X_train, y_train)
Out[72]:
Sensitivity Analysis¶
To compute SHAP value for the regression, we use LinearExplainer.
Build an explainer¶
In [73]:
explainer = shap.LinearExplainer(reg,
X_train,
feature_dependence="independent")
Compute SHAP values for test data¶
In [74]:
shap_values = explainer.shap_values(X_test)
shap_values[0]
Out[74]:
Plot the features importance¶
In [75]:
X_test_array = X_test.toarray()
shap.summary_plot(shap_values,
X_test_array,
feature_names=vectorizer.get_feature_names())

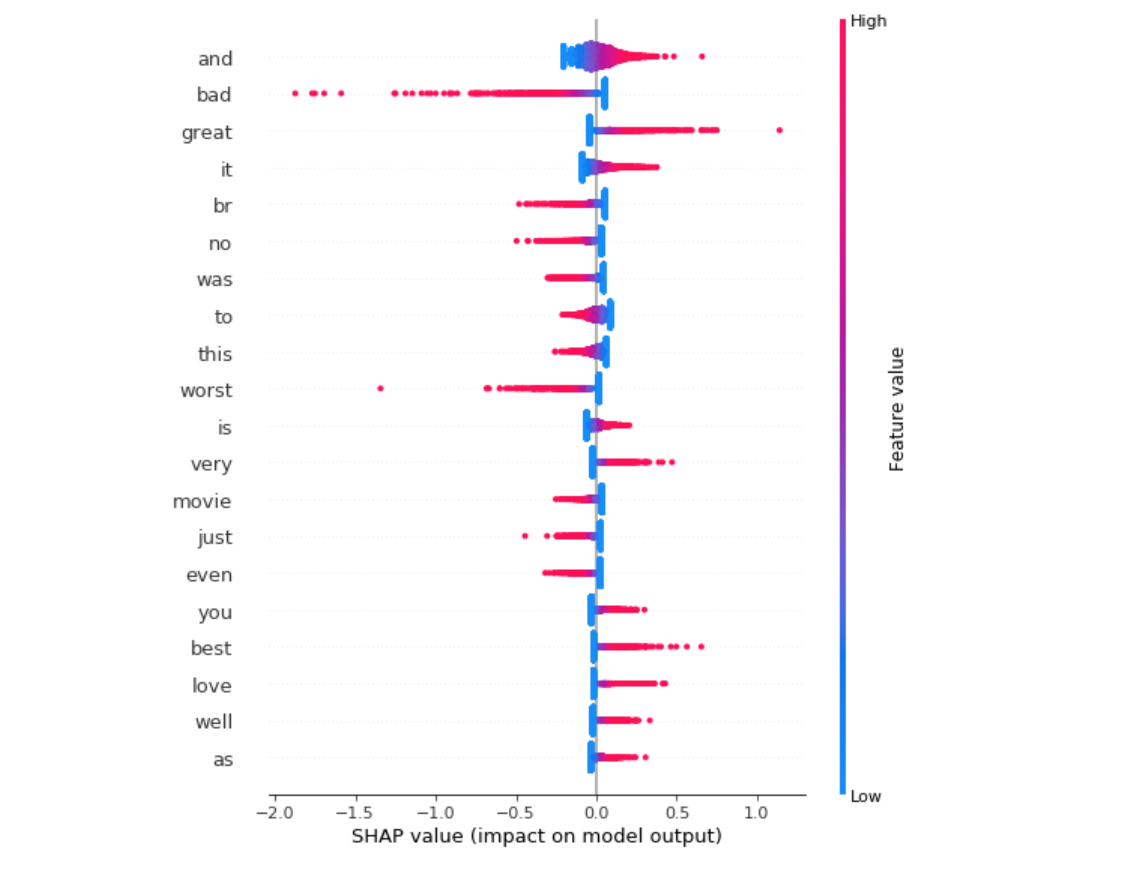
Plot the SHAP values for top features¶
In [101]:
# shap_values does not work since it is recognized as `list` and default to `bar` chart only.
# so it changed to shap_values[0]
shap.summary_plot(shap_values[0],
X_test_array,
feature_names=vectorizer.get_feature_names(),
plot_type='dot')

Explain the sentiment for one review¶
I tried to follow the example notebook Github - SHAP: Sentiment Analysis with Logistic Regression but it seems it does not work as it is due to json seriarization.
In [84]:
X_test_array[i, :]
Out[84]:
In [100]:
ind = 0
shap.force_plot(
explainer.expected_value, shap_values[0][ind,:], X_test_array[ind,:],
feature_names=vectorizer.get_feature_names()
)
Comments
Comments powered by Disqus