Train the image classifier using PyTorch
Goal¶
This post aims to introduce how to train the image classifier for MNIST dataset using PyTorch
Reference
Libraries¶
In [8]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Dataset
from sklearn.datasets import load_digits
# PyTorch
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
Functions¶
In [32]:
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.axis('off')
plt.show()
Load MNIST dataset¶
When downloading the image dataset, we also need to define transform function that apply pixel normalization from [0, 1] to [-1, +1]
In [50]:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))])
trainset = torchvision.datasets.MNIST(root='~/data',
train=True,
download=True,
transform=transform)
testset = torchvision.datasets.MNIST(root='~/data',
train=False,
download=True,
transform=transform)
Create a dataloader¶
In [13]:
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=100,
shuffle=True,
num_workers=2)
In [14]:
testloader = torch.utils.data.DataLoader(testset,
batch_size=100,
shuffle=False,
num_workers=2)
Define a model¶
In [6]:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3) # 28x28x32 -> 26x26x32
self.conv2 = nn.Conv2d(32, 64, 3) # 26x26x64 -> 24x24x64
self.pool = nn.MaxPool2d(2, 2) # 24x24x64 -> 12x12x64
self.dropout1 = nn.Dropout2d()
self.fc1 = nn.Linear(12 * 12 * 64, 128)
self.dropout2 = nn.Dropout2d()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.dropout1(x)
x = x.view(-1, 12 * 12 * 64)
x = F.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return x
Create a loss function and optimizer¶
In [10]:
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
Training a model¶
In [22]:
epochs = 5
for epoch in range(epochs):
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader, 0):
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 99:
print(f'[{epoch + 1}, {i+1}] loss: {running_loss / 100:.2}')
running_loss = 0.0
print('Finished Training')
Test¶
In [37]:
dataiter = iter(testloader)
images, labels = dataiter.next()
outputs = model(images)
_, predicted = torch.max(outputs, 1)
In [48]:
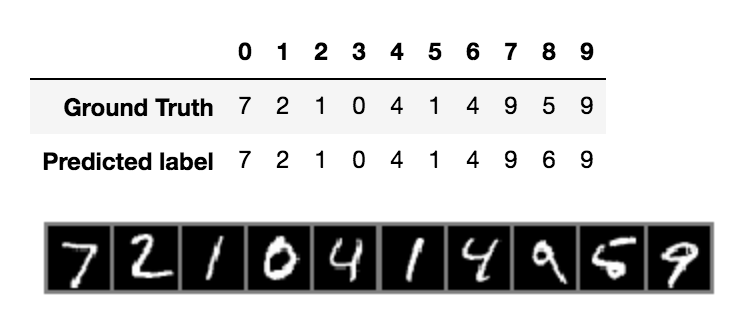
n_test = 10
df_result = pd.DataFrame({
'Ground Truth': labels[:n_test],
'Predicted label': predicted[:n_test]})
display(df_result.T)
imshow(torchvision.utils.make_grid(images[:n_test, :, :, :], nrow=n_test))

Comments
Comments powered by Disqus