One-Hot Encode Nominal Categorical Features
Goal¶
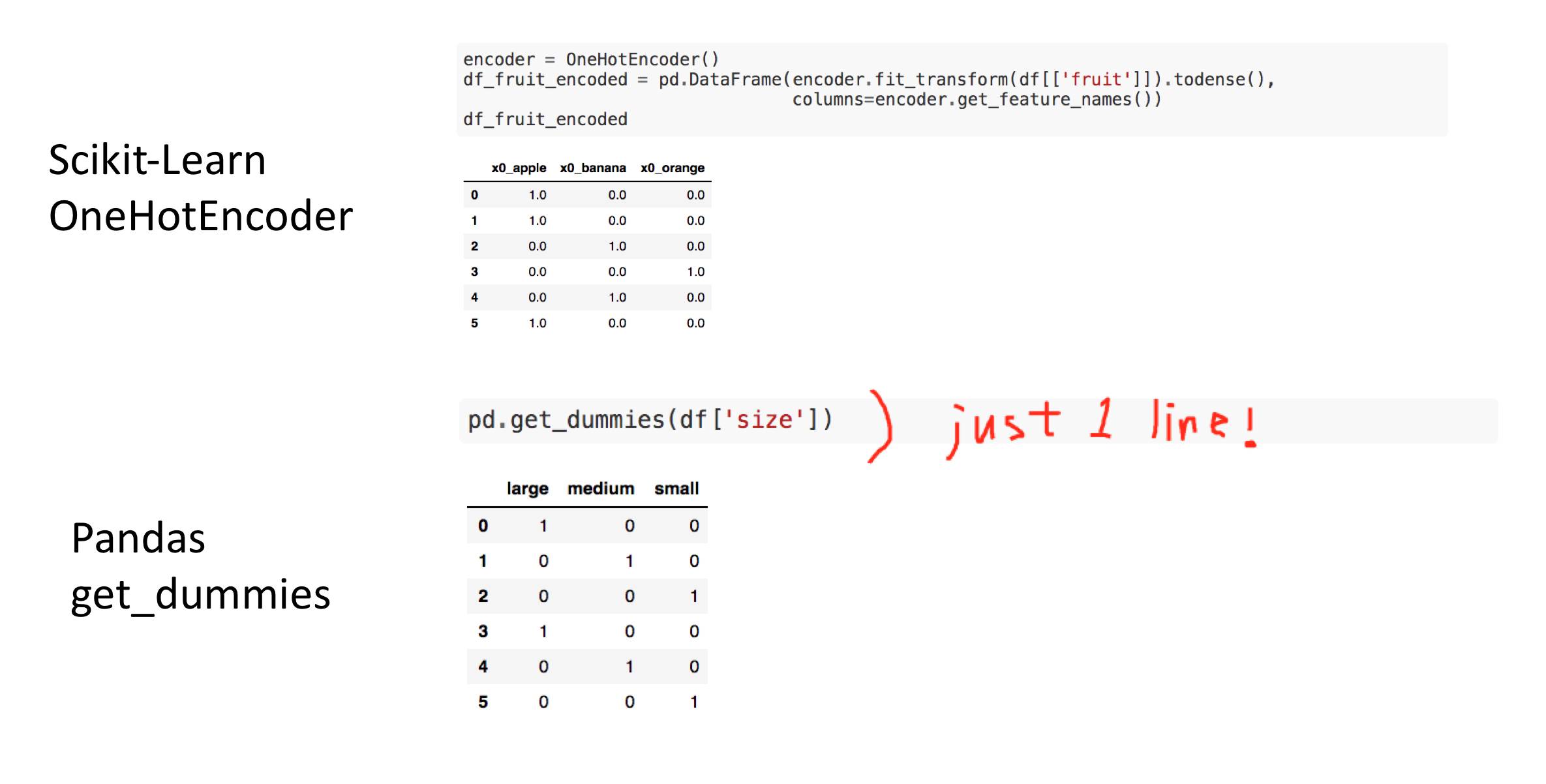
This post aims to introduce how to create one-hot-encoded features for categorical variables. In this post, two ways of creating one hot encoded features: OneHotEncoder in scikit-learn and get_dummies in pandas.
Peronally, I like get_dummies in pandas since pandas takes care of columns names, type of data and therefore, it looks cleaner and simpler with less code.
Reference