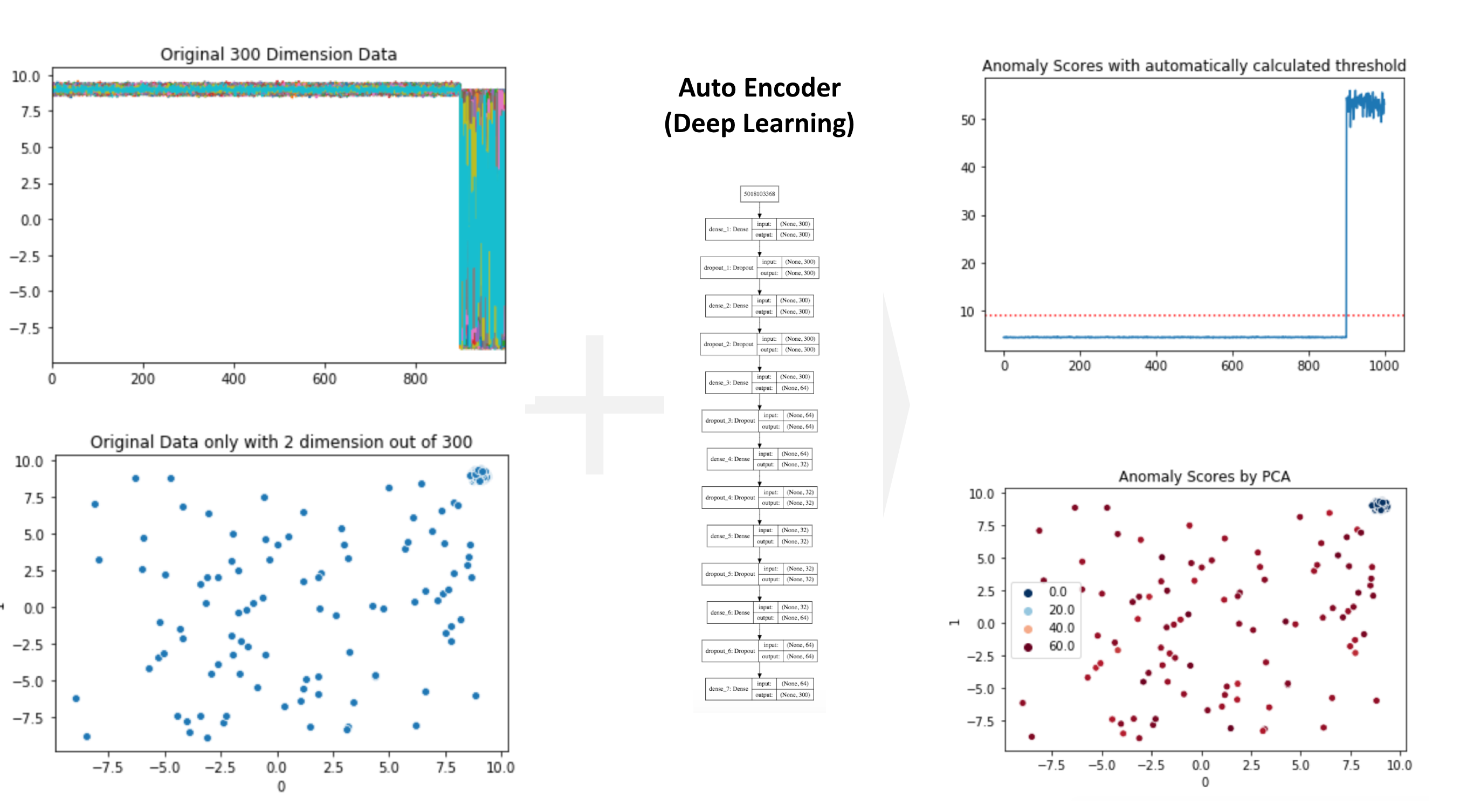
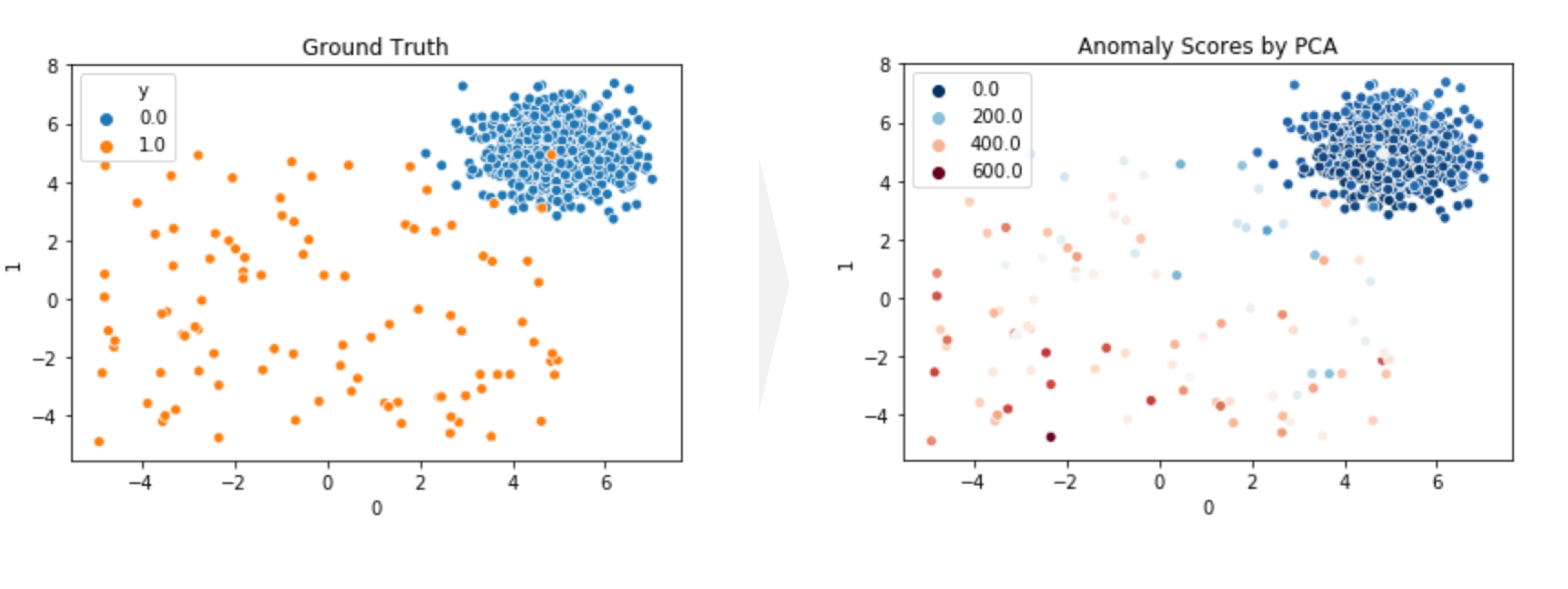
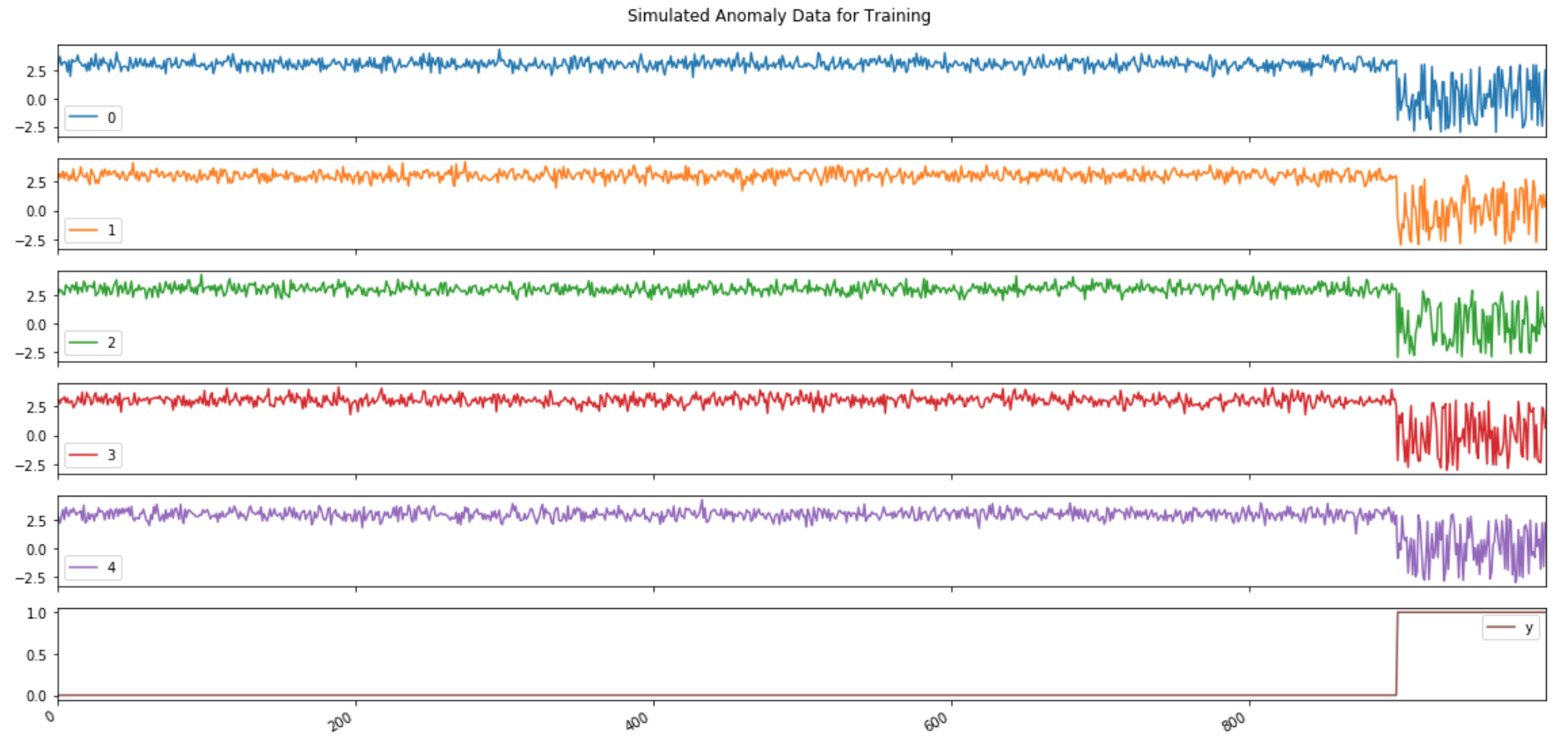
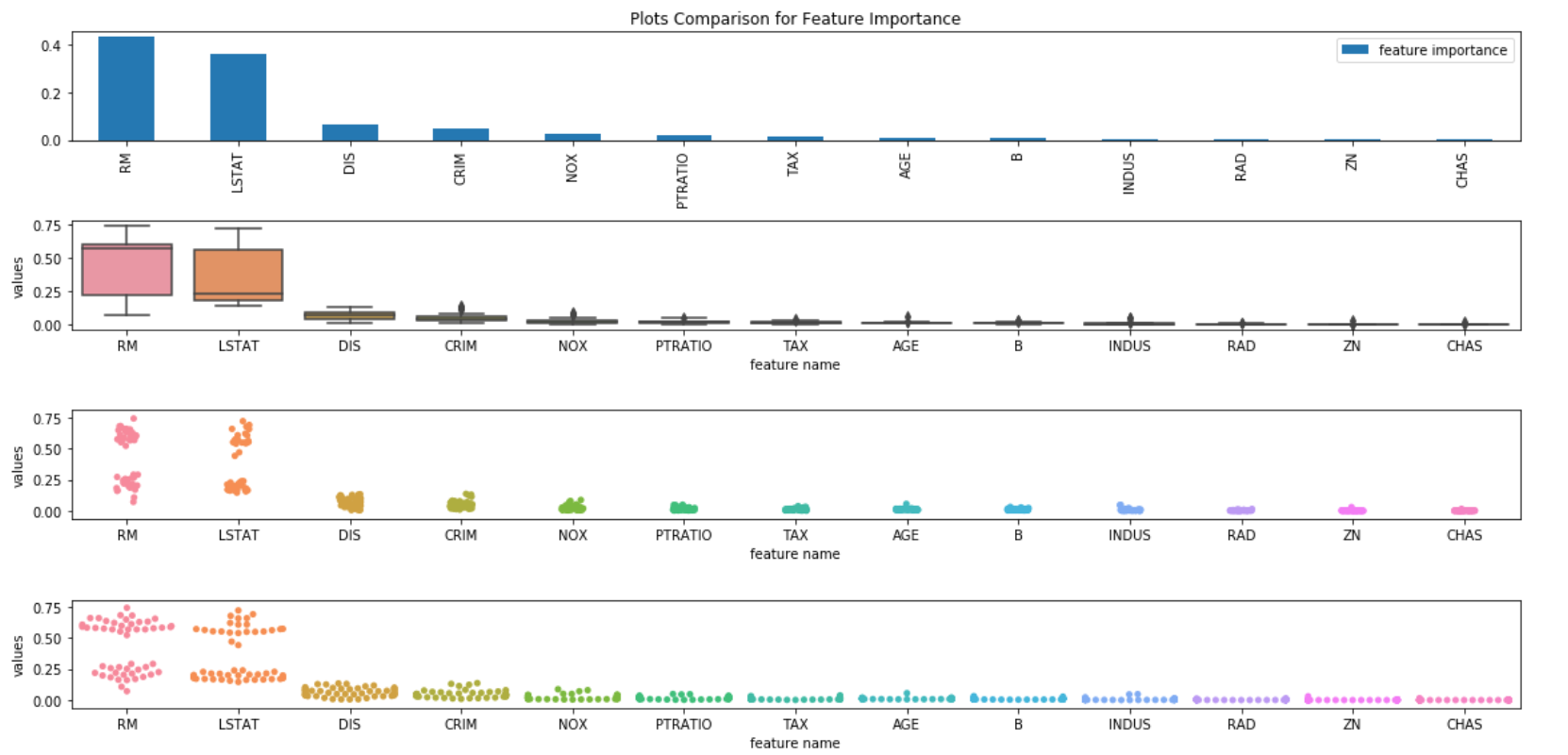
Loading Audio Data
Libraries¶
In [7]:
import pandas as pd
import numpy as np
from scipy.io import wavfile
import matplotlib.pyplot as plt
%matplotlib inline
Load a file as numpy¶
In [18]:
filename = '../data/sound00.wav'
fs, data = wavfile.read(filename)
data
Out[18]:
Visualize audio data¶
In [17]:
plt.figure(figsize=(16, 4))
plt.plot(data, lw=0.5, alpha=0.8);