Loading scikit-learn's MNIST Hand-Written Dataset
Goal¶
This post aims to introduce how to load MNIST (hand-written digit image) dataset using scikit-learn

Refernce
This post aims to introduce how to load MNIST (hand-written digit image) dataset using scikit-learn
Refernce
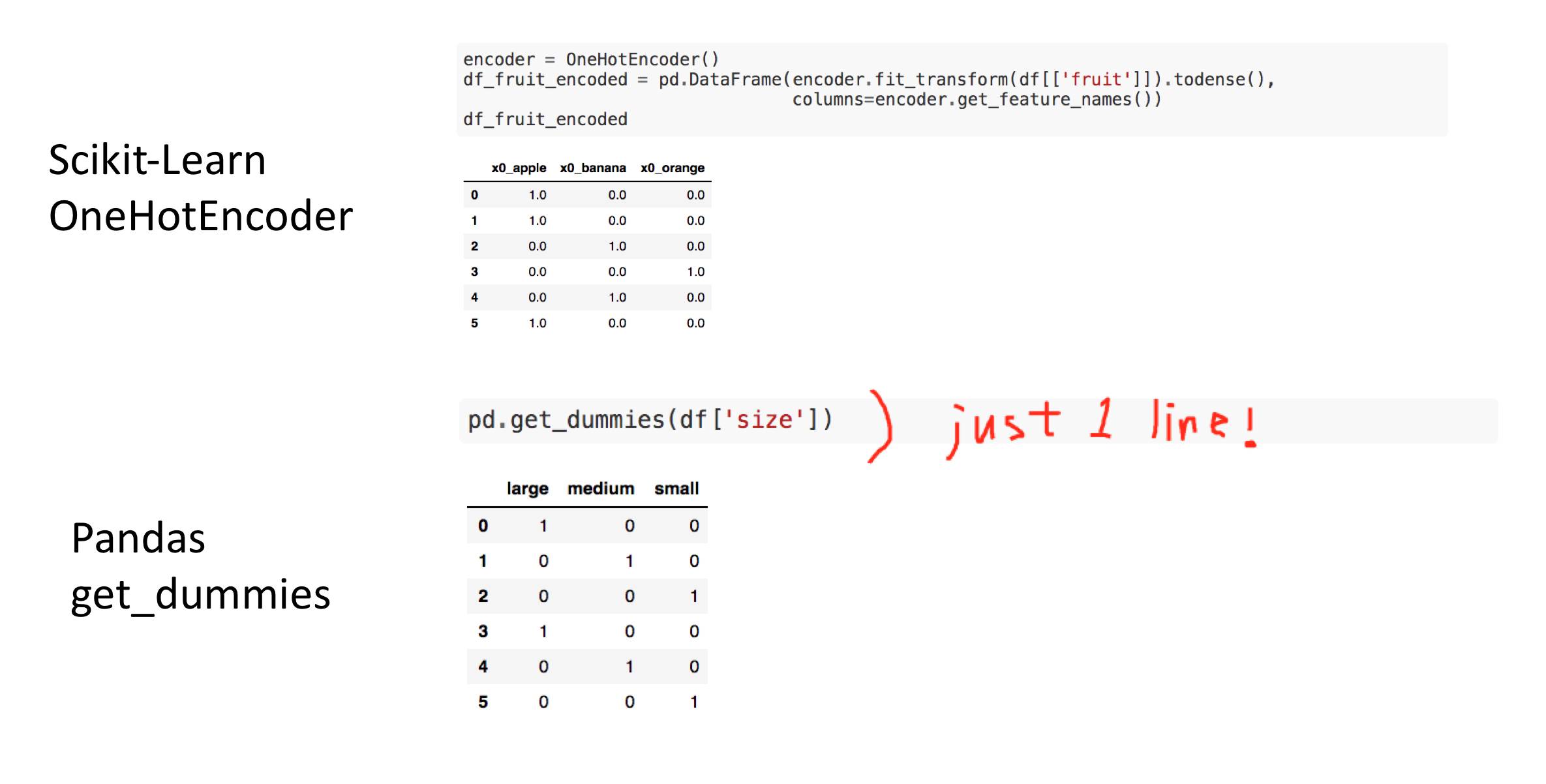
This post aims to introduce how to create one-hot-encoded features for categorical variables. In this post, two ways of creating one hot encoded features: OneHotEncoder in scikit-learn and get_dummies in pandas.
Peronally, I like get_dummies in pandas since pandas takes care of columns names, type of data and therefore, it looks cleaner and simpler with less code.
Reference
This post aims to introduce how to convert a dictionary into a matrix using DictVectorizer from scikit-learn. This is useful when you have data stored in a list of a sparse dictionary format and would like to convert it into a feature vector digestable in a scikit-learn format.

Reference
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
d_house= [{'area': 300.0, 'price': 1000, 'location': 'NY'},
{'area': 600.0, 'price': 2000, 'location': 'CA'},
{'price': 1500, 'location': 'CH'}
]
d_house
dv = DictVectorizer()
dv.fit(d_house)
pd.DataFrame(dv.fit_transform(d_house).todense(), columns=dv.feature_names_)
This post aims to introduce how to load Boston housing using scikit-learn
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
type(boston)
boston.keys()
pd.DataFrame(boston.data).head()
pd.DataFrame(boston.target).head()
print(boston.feature_names)
print(boston.DESCR)
This post aims to convert one of the categorical columns for further process using scikit-learn:
import pandas as pd
import sklearn.preprocessing
df = pd.DataFrame(data={'type': ['cat', 'dog', 'sheep'],
'weight': [10, 15, 50]})
df
Ordinal encoding is replacing the categories into numbers.
# Instanciate ordinal encoder class
oe = sklearn.preprocessing.OrdinalEncoder()
# Learn the mapping from categories to the numbers
oe.fit(df.loc[:, ['type']])
# Apply this ordinal encoder to new data
oe.transform(pd.DataFrame(['cat'] * 3 +
['dog'] * 2 +
['sheep'] * 5))
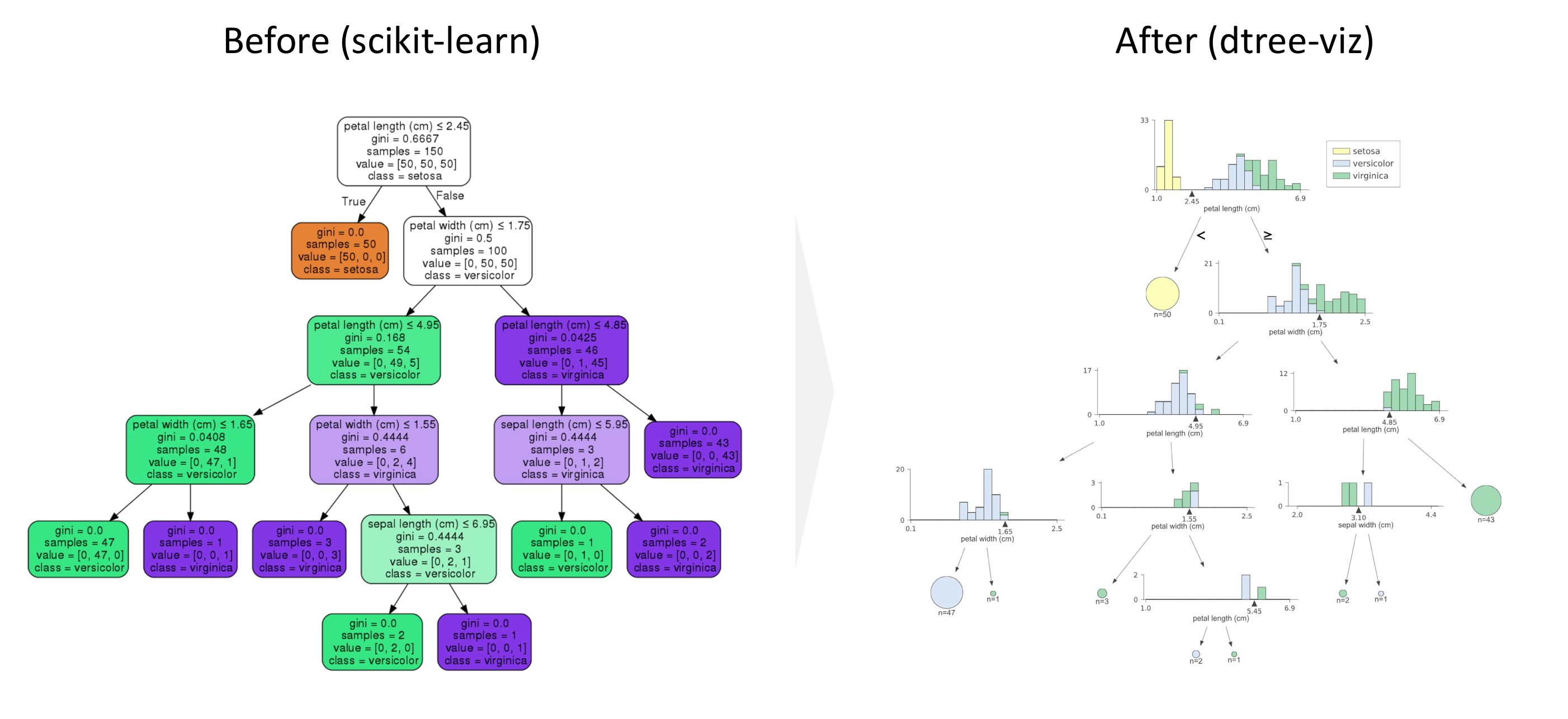
The goal in this post is to introduce dtreeviz to visualize a decision tree for classification more nicely than what scikit-learn can visualize. We will walk through the tutorial for decision trees in Scikit-learn using iris data set.
Note that if we use a decision tree for regression, the visualization would be different.